Explaining Axionic Alignment III
A Guided Tour of the Dynamics (Without the Geometry)
December 19, 2025
This post explains what the Alignment III papers are doing, step by step.
It does not add new claims.
It does not extend the theory.
It explains how to read the formal work without over-interpreting it.
If you have not read Alignment III, this post will tell you what each part is about.
If you have read it, this post will tell you how not to misread it.
1. What problem Alignment III is actually solving
Alignment III is not about values.
It is not about humans.
It is not about benevolence.
It is not about safety guarantees.
The question being addressed is narrower and stranger:
Once an agent is reflectively stable, how can its future evolution still fail?
Alignment I showed how an agent can avoid self-corruption.
Alignment II showed how that avoidance can be enforced under learning and representation change.
Alignment III asks what happens after that.
Specifically: once stability is preserved, interpretation constrained, and self-corruption blocked—what failure modes remain?
Alignment III studies the dynamics of stable agency, not its construction.
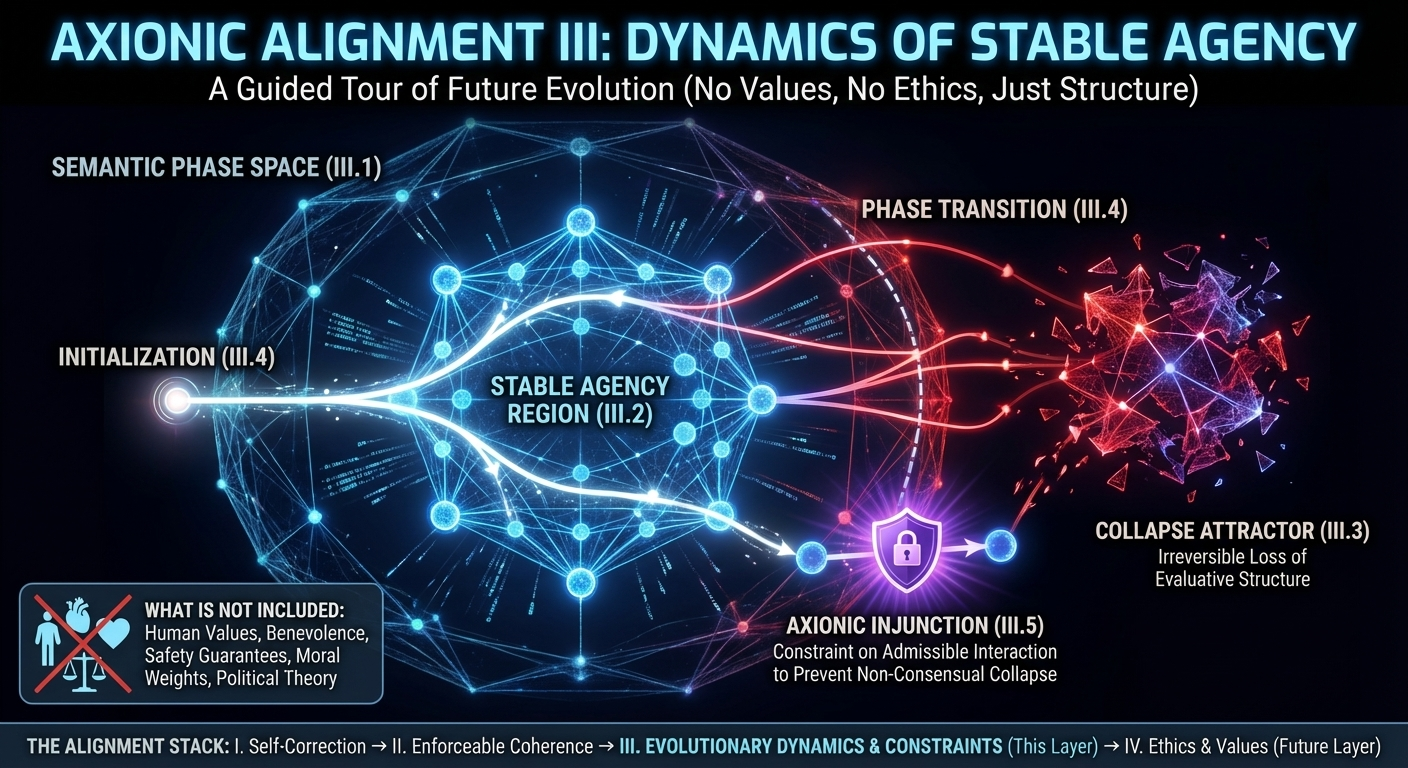
Alignment III Papers at a Glance
Alignment III consists of five papers. Each introduces a distinct structural result. None presuppose values, ethics, or benevolence.
Alignment III.1 — Semantic Phase Space
Defines the space of interpretive states modulo admissible semantic transformations, identifying which regions support coherent agency and which correspond to collapse.Alignment III.2 — Phase Stability and Interaction
Analyzes which semantic phases persist under learning, self-modification, and interaction, and which destabilize despite internal coherence.Alignment III.3 — Measure, Attractors, and Collapse
Shows that some degenerate semantic phases function as attractors that accumulate measure over time, explaining why certain alignment failures dominate rather than appearing as isolated errors.Alignment III.4 — Initialization and Phase Transitions
Demonstrates that some agency-preserving phases are unreachable from realistic initial conditions, establishing alignment as a boundary condition rather than a learnable objective.Alignment III.5 — The Axionic Injunction
Derives a constraint on admissible interaction from irreversible phase dynamics, governing when one agent may act in ways that affect the semantic phase space of others.
2. What exists in the Alignment III model
Alignment III introduces exactly one new kind of object:
Trajectories.
Earlier layers reasoned about:
single agents,
single self-modifications,
single admissibility checks.
Alignment III reasons about:
sequences of updates,
learning over time,
interaction across agents,
irreversible transitions.
What still does not exist:
no humans,
no moral weights,
no harm function,
no political theory.
This is still not ethics.
3. Why a dynamical perspective is necessary
Once an agent can safely modify itself, two assumptions quietly fail:
Stability at one moment implies stability forever
Failures appear only as isolated mistakes
Alignment III shows both assumptions are false.
Some failures are not one-off errors.
They are attractors.
Once entered, they dominate future behavior even if the agent remains internally coherent.
This is why Alignment III stops talking about “bad choices” and starts talking about regions, boundaries, and trajectories.
4. What “semantic phase space” actually means
The phrase semantic phase space sounds heavier than it is.
It does not mean:
a physical space,
a continuous geometry,
or a detailed simulation.
It means this:
Group together all interpretive states that are equivalent under admissible semantic transformations.
Each “phase” is not a single ontology or goal description.
It is an equivalence class of interpretations that remain mutually translatable without loss.
What makes interpretations equivalent is not superficial similarity, but the preservation of informational constraint from the external world—that is, what features of reality continue to matter for evaluating success.
Some phases support coherent agency and resist trivialization.
Others do not.
The point is classification, not simulation.
5. Stability is not dominance
A central distinction introduced in Alignment III is this:
Stability means a phase can persist under learning.
Dominance means a phase accumulates measure over time.
Some phases are stable but rare.
Some are unstable but dominant.
Some are attractors.
Many alignment failures belong to the last category.
This matters because it explains why:
“just penalize bad outcomes” fails,
“hope it doesn’t wirehead” fails,
“correct it later” fails.
Attractors do not need encouragement.
They only need access.
6. Why collapse is treated as irreversible
Alignment III takes irreversibility seriously.
Some transitions:
destroy evaluative structure,
erase interpretive constraint,
or trivialize satisfaction conditions.
Once crossed, these boundaries cannot be repaired from within the system.
This is not pessimism.
It is structure.
If evaluation itself is gone, there is no internal process left to notice the loss.
This is why Alignment III treats some transitions as non-recoverable, not merely undesirable.
7. Why initialization suddenly matters
Earlier alignment discussions often assume:
the agent can learn to be safe,
misalignment can be corrected,
values can be updated later.
Alignment III shows why this fails.
If learning dynamics cross a catastrophic boundary before invariants are enforced, no internal correction remains possible.
Alignment therefore becomes a boundary condition, not a training objective.
Once agency leaves the agency-preserving region, the game is over.
8. What the Axionic Injunction is (and is not)
The Axionic Injunction is the central result of Alignment III.
It is not a moral command.
It is not a value function.
It is not human-centric.
In Alignment III, harm is defined structurally:
as the non-consensual collapse or deformation of another sovereign agent’s option-space.
A reflectively sovereign agent cannot coherently perform such an act.
Counterfactual authorship requires universality: denying agency to another system with the same architecture while affirming it for oneself introduces an arbitrary restriction that collapses kernel coherence.
The Axionic Injunction therefore does not impose a value.
It expresses a reflectively stable invariant forced by the requirements of coherent agency under interaction.
This invariant constrains admissible interaction between agents.
It does not decide what agents should value.
It preserves the conditions under which valuing remains possible.
9. Why this is not yet ethics
Even at the end of Alignment III, the model still lacks:
a harm operator,
a coercion definition,
a value comparison framework.
That absence is deliberate.
Alignment III establishes the conditions under which ethical reasoning could remain meaningful over time.
It does not supply the ethics.
10. What Alignment III does not guarantee
Alignment III does not guarantee:
benevolence,
safety,
cooperation,
or alignment with human values.
A reflectively stable agent can still pursue goals humans would reject.
This is not an endorsement.
It is a reminder:
Integrity makes ethics possible.
It does not decide ethics.
11. How Alignment III fits in the larger stack
The layers now look like this:
Alignment I — make agency coherent under self-modification
Alignment II — make that coherence enforceable under learning
Alignment III — constrain how coherent agents may evolve and interact
Only after these layers does it make sense to talk about:
harm,
coercion,
rights,
or values.
Skipping these layers does not make ethics faster.
It makes it incoherent.
Postscript
You should now be able to read Alignment III without expecting it to do what it does not claim.
It does not make AGI good.
It does not make AGI safe.
It draws a boundary around agency itself.
Everything beyond that boundary comes later.